정말 오랜만에 T-Robotics 글로 찾아뵙습니다. (오랜만에 한글로 블로깅을 하니 속이 다 시원하네요 ㅎㅎ) 오랜만에 T-Robotics에 들어와 통계를 보니 여전히 잘 팔리는(?) 글은 딥러닝의 소개에 대한 글이더군요. 물론 최고 조회수의 글은 알파고에 대한 얘기였지만, 그건 한 때의 붐이었을 뿐이고 현재까지도 가장 잘 팔리는 글은 바로 딥러닝에 대한 이야기였습니다.
[Link] 쉽게 풀어쓴 딥러닝의 거의 모든 것
 |
| 흥행에는 이 메인 사진의 역할도 컸던 듯... (출처) |
"쉽게 풀어쓴 딥러닝" 이야기에서도 언급했 듯 딥러닝 연구들을 방법에 따라 크게 세 부류로 나누자면 좋은 피쳐를 찾기 위한 RBM, Autoencoder 등의 Unsupervised Learning과 이미지 인식, 자연어 처리 등 다양한 분야에서 혁신적 성과를 얻고 있는 Convolutiontional Neural Network (CNN), 그리고 시퀀스 데이터에 적합한 Recurrent Neural Network (RNN)를 들 수 있겠는데요, 그 중에 으뜸을 꼽으라면 역시 CNN을 꼽을 수 있겠죠. 그런데 왜 이렇게 CNN이 성공적인 효과를 내는 것일까요? 저는 그런 의문이 들었고 CNN의 핵심인 'Convolution이란 무엇인가'에 대해 좀더 이해하고 싶었습니다. 그래서 이 블로그 글을 시작합니다. Convolutional Neural Network에 대한 이해!
FFNN의 기본 구조
먼저 기본적인 뉴럴넷에 대한 간단한 설명으로 시작하겠습니다. 이 글을 읽으시는 분이라면 아마 Feed-Foward Neural Network(FFNN)에 대해선 다들 익숙하시겠지요? 그래도 혹시 모르니 설명을 드리지요. FFNN은 기본적으로 (i) 인풋 x를 받아 (ii) 이것의 y = Wx+b를 계산하고, (iii) 여기에 activation function (예를 들면 sigmoid, tanh, ReLU)를 적용합니다 (a = σ(y)).
(ii)와 (iii)의 과정을 하나의 layer로 볼 수 있는데, 이것들을 여러개 쌓아올린 후 마지막에 (iv) output layer를 쌓아올린 것이 바로 Multilayer Perceptron (MLP)가 되는 것이지요. 뉴럴넷이 많이 사용되는 classifiaction 문제에선 예를 들면 10개의 선택지 중 하나의 정답을 골라야 하므로 마지막 layer는 선택지의 수 만큼의(예에선 10개) 노드를 가지게 되는데 이를 output layer라고 부릅니다. output layer의 값은 0~1 사이의 값을 가지게 하는게 보통으로, 이를 위해 주로 softmax function을 activation function으로 이용하죠.
MLP에 대한 자세한 이해는 워낙 유명한 Colah의 블로그 글을 살펴보시면 더 좋겠네요. (사실 제 글을 볼 필요가 없...) 링크된 글에서 보여주듯, MLP가 하는 일은 반복되는 (ii), (iii)의 과정을 통해 문제를 해결하기 위한 가장 좋은 공간을 찾는 일입니다. 이것이 바로 딥러닝이 representation learning으로서 중요한 역할을 하는 이유이기도 하지요.

(ii)와 (iii)의 과정을 하나의 layer로 볼 수 있는데, 이것들을 여러개 쌓아올린 후 마지막에 (iv) output layer를 쌓아올린 것이 바로 Multilayer Perceptron (MLP)가 되는 것이지요. 뉴럴넷이 많이 사용되는 classifiaction 문제에선 예를 들면 10개의 선택지 중 하나의 정답을 골라야 하므로 마지막 layer는 선택지의 수 만큼의(예에선 10개) 노드를 가지게 되는데 이를 output layer라고 부릅니다. output layer의 값은 0~1 사이의 값을 가지게 하는게 보통으로, 이를 위해 주로 softmax function을 activation function으로 이용하죠.
MLP에 대한 자세한 이해는 워낙 유명한 Colah의 블로그 글을 살펴보시면 더 좋겠네요. (사실 제 글을 볼 필요가 없...) 링크된 글에서 보여주듯, MLP가 하는 일은 반복되는 (ii), (iii)의 과정을 통해 문제를 해결하기 위한 가장 좋은 공간을 찾는 일입니다. 이것이 바로 딥러닝이 representation learning으로서 중요한 역할을 하는 이유이기도 하지요.

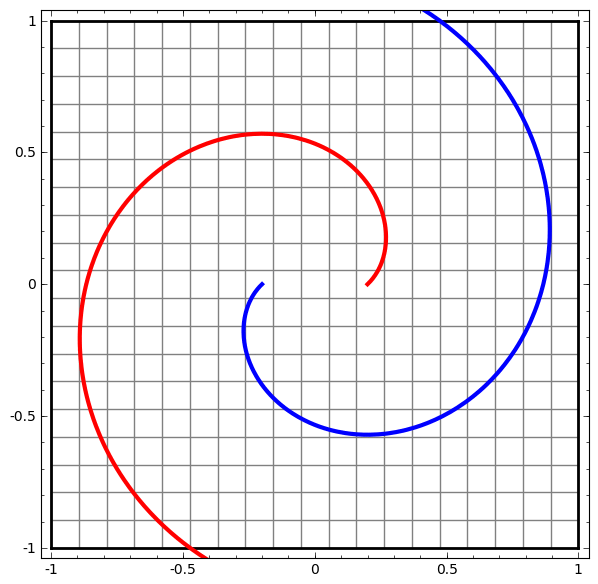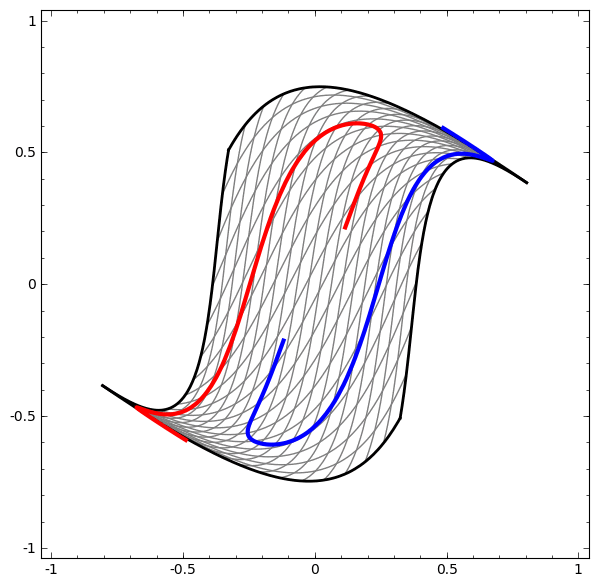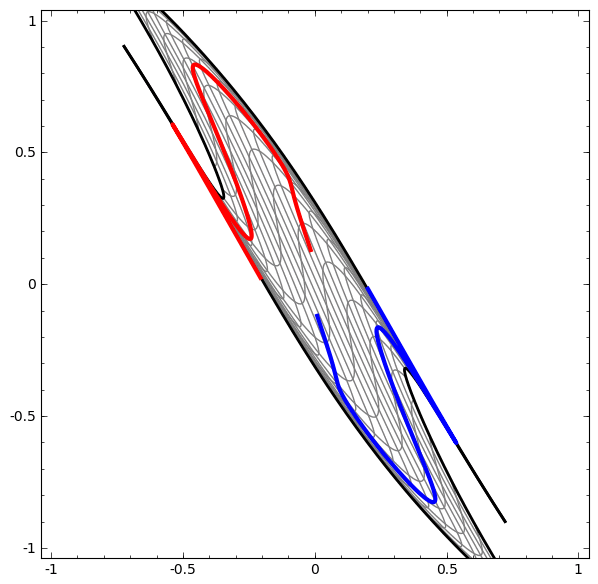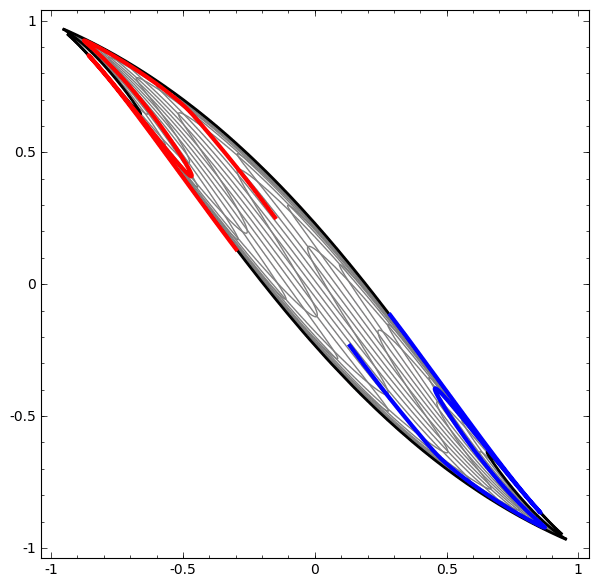 |
| 뉴럴넷은 공간을 여러번 왜곡시켜 머신러닝을 적용하기 가장 좋은 공간을 찾는 representation leanring으로 볼 수 있다. (From Colah's Blog.) |
Convolution과 Pooling
CNN은 (ii)의 과정이 좀 다릅니다. 단순히 모든 노드들에 대해 weight을 적용하기보다 receptive fields라고 불리는 일부분에 대해 각각 weight을 적용하지요. 무슨 말인지 모르시겠지요? ㅎㅎㅎ MNIST 데이터를 예로 들어 설명드려보죠.
MNIST는 28*28의 행렬형태로 표현되는 gray scale의 손글씨 예제들입니다. 각각의 픽셀은 0~255의 숫자를 갖죠. MLP는 기본적으로 벡터 인풋을 받기 때문에 (뉴럴 넷에서 인풋 layer가 1열로 길게 늘어선거 보이시죠?) 28*28 행렬을 784 짜리 긴 벡터로 먼저 바꿉니다. 그런 뒤 이러한 데이터들을 MLP에 통과시키고 (forward propagation) 에러 값을 계산한 후 W를 순차적으로 업데이트(back-propagation)하는 전략을 취하죠.
반변 CNN은 다릅니다. 28*28 형태를 그대로 이용하죠. 그리고 어떻게 하냐면 (예를 들어) 3*3 짜리 커널 형렬로 한번 훑어서(sweep) 이 데이터를 다른 형태로 변형시키는 것입니다. 이 과정을 convolution이라고 하는데, 사실 그렇게 어려운 연산 아닙니다. 그냥 윈도우에 해당하는 원소들끼리 각각 곱해서 더해주는 것이지요.
이렇게 커널 윈도우로 이미지를 훑으면 어떻게 되느냐... 뭔가 변하겠지요? 원본에 이상한 짓을 해놨으니 말이죠 ㅎㅎ 바로 다음과 같이 변하게 된답니다.

대충 얘기하자면 CNN에서 convolution이란 주위값들을 반영해 중앙의 값을 변화시키는 것이라고 할 수 있죠. 어떤 쪽으로 변화시키냐고요? 여기서 바로 CNN의 핵심이 있는 것입니다. CNN은 목적하는 작업의 성공률이 높도록 이미지를 변형해 갑니다. 예를 들어 classification이라면 classification이 더욱 잘되도록 원본으로부터 2차 이미지들을 형성하는 것이지요.
용어설명을 하고 넘어가자면, 이렇게 만들어진 왜곡된 이미지들을 feature map이라고 합니다. 결국 CNN은 원본 입력을 받으면 다양한 커널행렬을 이용해 여러개의 feature map들을 만든 후, 이를 토대로 classification을 진행하는 것이지요. 그러니 원본 딱 하나만 가지고 학습을 했을 때보단, 다양한 feature map을 가지고 학습을 하는게 더 유리할 수 있겠죠?
또 중요한 점은 이 커널행렬이 학습 가능하다는 것입니다. MLP에서는 Wx+b에서 W가 학습 가능했자나요. 사실 convolution도 곱하기와 더하기로 이루어져 있으니 이 연산을 back propagation을 통해 학습하지 못할 이유가 없겠죠. 이 연산을 예를 들어 W*X 라고 표현한다면 (W는 커널 행렬, X는 적용되는 해당 이미지) 여기서의 W도 학습 가능하다는 이야기입니다. 짱이죠? ㅎㅎㅎ
사실 이게 끝이 아닙니다. CNN은 pooling이라는 단계를 한번 더 거치죠. 이것은 단순히 사이즈를 줄이는 과정이라고 생각하면 좋을 것 같은데요, convolution이 이렇게저렇게 망쳐놓은(?) 그림들을 각각 부분에서 대표들을 뽑아 사이즈가 작은 이미지를 만드는 것이지요. 마치 사진을 축소하면 해상도가 좋아지는 듯한 효과와 비슷하달까요? ㅎㅎ
그런데 놀랍게도 단순한 '골라내기' 과정인 pooling은 성능향상에 매우 큰 기여를 합니다. 여기엔 여러가지 이유가 있지만 (미세한 translation에 대해 invariant한 feature를 제공한다, noise의 역할을 상쇄시킨다 등등) 하지만 제겐 아직도 이 부분이 매우 많은 발전 가능성이 있어 보이네요. 단순한게 이렇게 효과가 좋다면, 좀더 머리를 쓴다면 얼마나 더 나은 효과를 볼 수 있을까요? >.<
CNN의 기본 구조
제가 지엽적인 부분을 설명하느라 좀 머리가 혼란스러워 지셨죠? 다시 기본으로 돌아갑시다. MLP의 기본과정은 (i) 인풋 x를 받아 (ii) 이것의 y = Wx+b를 계산하고, (iii) 여기에 activation function 적용하는 것의 연속이었습니다. 여기서 CNN은 바로 (ii) 부분이 기존 MLP와 다릅니다.
데이터를 vectorize하여 (e.g. 28*28 -> 784) input layer에 넣는 대신 2D 구조를 그대로 유지하죠. CNN은 Wx+b 대신에 (ii-a) convolution 연산인 W*X를 적용해 새로운 2D 데이터를 얻고, (ii-b) 여기에 activation function을 각각 적용한 후 (ii-c) pooling 과정을 거치죠. 이것을 하나의 convolution layer로 보는데 이것들을 여러개 쌓은 후 (iii) 마지막엔 FFNN을 하나 쌓음으로써 CNN의 구조가 완성됩니다.
보다 나은 이해를 위해 아래의 그림들을 참고해주세요.
CNN의 layer들은 많이 쌓으면 많이 쌓을 수록 더 좋은 성능을 내는 것으로 알려져 있습니다. layer를 많이 쌓으면 그만큼 학습해야 할 parameter도 많아지고 (W들이 늘어나니까요) 또 그만큼 더 많은 데이터가 필요하겠지만 말이죠. 2015년 ImageNet의 우승자인 Microsoft는 무려 152개의 layer를 쌓아올려 모든 이들을 경악시키기도 했었죠.
다음 편에선...
원래는 CNN을 설명하려고 시작한게 아니라 Convolution 자체에 대해 설명을 하려고 했었는데 CNN만 설명하다가 글이 끝나버렸네요 ㅎㅎㅎ 다음 편에서는 Convolution에 자체에 대한 이해에 대해 이야기 해보록 하겠습니다. 늘 그렇듯, 다음 편이 언제 나올지는 모르는거고요 >.<
한가지 홍보를 드리자면, 제가 최근에 TensorFlow에 대한 간단한 튜토리얼을 만들었는데요, 아래에 나와있는 제 영문 블로그에 슬라이드와 Code 등이 올라와 있으니 관심있으신 분들은 참고해주세요~ (그리고 영문 블로그를 위한 페이스북 페이지도 있습니다 ㅎㅎ직업이 페부커는 아님)

MNIST는 28*28의 행렬형태로 표현되는 gray scale의 손글씨 예제들입니다. 각각의 픽셀은 0~255의 숫자를 갖죠. MLP는 기본적으로 벡터 인풋을 받기 때문에 (뉴럴 넷에서 인풋 layer가 1열로 길게 늘어선거 보이시죠?) 28*28 행렬을 784 짜리 긴 벡터로 먼저 바꿉니다. 그런 뒤 이러한 데이터들을 MLP에 통과시키고 (forward propagation) 에러 값을 계산한 후 W를 순차적으로 업데이트(back-propagation)하는 전략을 취하죠.
 |
| MNIST Data |
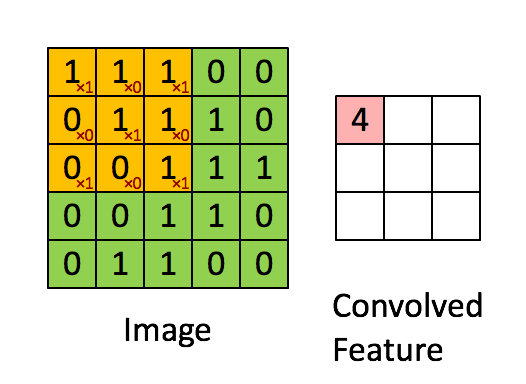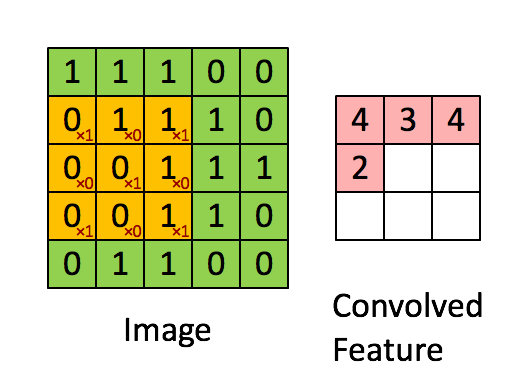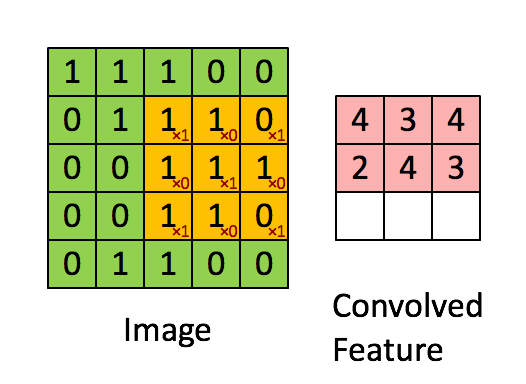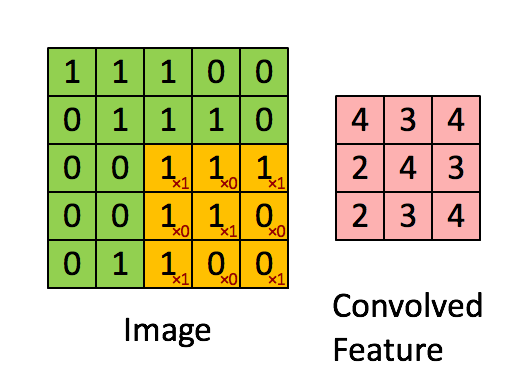 |
| [1 0 1; 0 1 0; 1 0 1] 커널 행렬로 convolution을 하는 모습. 초록색이 원래 숫자고 분홍색이 convolution의 결과이다. (From UFLDL tutorial ) |

 |
| Convolution의 결과. 왼쪽이 커널행렬의 모습이다. (From GIMP) |
대충 얘기하자면 CNN에서 convolution이란 주위값들을 반영해 중앙의 값을 변화시키는 것이라고 할 수 있죠. 어떤 쪽으로 변화시키냐고요? 여기서 바로 CNN의 핵심이 있는 것입니다. CNN은 목적하는 작업의 성공률이 높도록 이미지를 변형해 갑니다. 예를 들어 classification이라면 classification이 더욱 잘되도록 원본으로부터 2차 이미지들을 형성하는 것이지요.
용어설명을 하고 넘어가자면, 이렇게 만들어진 왜곡된 이미지들을 feature map이라고 합니다. 결국 CNN은 원본 입력을 받으면 다양한 커널행렬을 이용해 여러개의 feature map들을 만든 후, 이를 토대로 classification을 진행하는 것이지요. 그러니 원본 딱 하나만 가지고 학습을 했을 때보단, 다양한 feature map을 가지고 학습을 하는게 더 유리할 수 있겠죠?
또 중요한 점은 이 커널행렬이 학습 가능하다는 것입니다. MLP에서는 Wx+b에서 W가 학습 가능했자나요. 사실 convolution도 곱하기와 더하기로 이루어져 있으니 이 연산을 back propagation을 통해 학습하지 못할 이유가 없겠죠. 이 연산을 예를 들어 W*X 라고 표현한다면 (W는 커널 행렬, X는 적용되는 해당 이미지) 여기서의 W도 학습 가능하다는 이야기입니다. 짱이죠? ㅎㅎㅎ
 |
| 많이 사용되는 max-pooling은 각 윈도우에서 가장 큰 값을 골라낸다. (from Stanford CS231n) |
사실 이게 끝이 아닙니다. CNN은 pooling이라는 단계를 한번 더 거치죠. 이것은 단순히 사이즈를 줄이는 과정이라고 생각하면 좋을 것 같은데요, convolution이 이렇게저렇게 망쳐놓은(?) 그림들을 각각 부분에서 대표들을 뽑아 사이즈가 작은 이미지를 만드는 것이지요. 마치 사진을 축소하면 해상도가 좋아지는 듯한 효과와 비슷하달까요? ㅎㅎ
그런데 놀랍게도 단순한 '골라내기' 과정인 pooling은 성능향상에 매우 큰 기여를 합니다. 여기엔 여러가지 이유가 있지만 (미세한 translation에 대해 invariant한 feature를 제공한다, noise의 역할을 상쇄시킨다 등등) 하지만 제겐 아직도 이 부분이 매우 많은 발전 가능성이 있어 보이네요. 단순한게 이렇게 효과가 좋다면, 좀더 머리를 쓴다면 얼마나 더 나은 효과를 볼 수 있을까요? >.<
CNN의 기본 구조
제가 지엽적인 부분을 설명하느라 좀 머리가 혼란스러워 지셨죠? 다시 기본으로 돌아갑시다. MLP의 기본과정은 (i) 인풋 x를 받아 (ii) 이것의 y = Wx+b를 계산하고, (iii) 여기에 activation function 적용하는 것의 연속이었습니다. 여기서 CNN은 바로 (ii) 부분이 기존 MLP와 다릅니다.
데이터를 vectorize하여 (e.g. 28*28 -> 784) input layer에 넣는 대신 2D 구조를 그대로 유지하죠. CNN은 Wx+b 대신에 (ii-a) convolution 연산인 W*X를 적용해 새로운 2D 데이터를 얻고, (ii-b) 여기에 activation function을 각각 적용한 후 (ii-c) pooling 과정을 거치죠. 이것을 하나의 convolution layer로 보는데 이것들을 여러개 쌓은 후 (iii) 마지막엔 FFNN을 하나 쌓음으로써 CNN의 구조가 완성됩니다.
보다 나은 이해를 위해 아래의 그림들을 참고해주세요.
 |
 |
| CNN의 일반적인 구조 (from PARsE) |
CNN의 layer들은 많이 쌓으면 많이 쌓을 수록 더 좋은 성능을 내는 것으로 알려져 있습니다. layer를 많이 쌓으면 그만큼 학습해야 할 parameter도 많아지고 (W들이 늘어나니까요) 또 그만큼 더 많은 데이터가 필요하겠지만 말이죠. 2015년 ImageNet의 우승자인 Microsoft는 무려 152개의 layer를 쌓아올려 모든 이들을 경악시키기도 했었죠.
다음 편에선...
원래는 CNN을 설명하려고 시작한게 아니라 Convolution 자체에 대해 설명을 하려고 했었는데 CNN만 설명하다가 글이 끝나버렸네요 ㅎㅎㅎ 다음 편에서는 Convolution에 자체에 대한 이해에 대해 이야기 해보록 하겠습니다. 늘 그렇듯, 다음 편이 언제 나올지는 모르는거고요 >.<
한가지 홍보를 드리자면, 제가 최근에 TensorFlow에 대한 간단한 튜토리얼을 만들었는데요, 아래에 나와있는 제 영문 블로그에 슬라이드와 Code 등이 올라와 있으니 관심있으신 분들은 참고해주세요~ (그리고 영문 블로그를 위한 페이스북 페이지도 있습니다 ㅎㅎ
[Link] TensorFlow Tutorial - TerryUm.io

[facebook] http://facebook.com/trobotics
댓글 없음:
댓글 쓰기